Parallelisierung mit Open MP in C++
Dank Parallelisierung mit Open MP kann man C++ Programme deutlich beschleunigen. In diesem Artikel gebe ich eine kurze Einführung wie man Open MP in einem einfachen C++ Beispiel einsetzt. Erst bei mehrfacher Ausführung wird klar, dass die Codeteile immer in einer anderen Anzahl von Threads bearbeitet wird.
Parallelisierung mit Open MP in C++
Lange Zeit hatten Computer einen einzigen Prozessor. Schon in den 80er Jahren des letzten Jahrhunderts kamen dann Co-Prozessoren dazu, damit man beispielsweise Fließkommaberechnungen effizienter durchführen kann. Aus dieser Optimierung entstand die heutige GPU, ein Prozessor spezialisiert für diese Berechnungen die fast ausschließlich für die 3D Berechnung verwendet wird. Ende der 90er Jahre wurden Mehrkern Prozessoren eingeführt. Eine CPU bestand aus 2, dann 4 und heute 8, 16 oder mehr eigenständiger Prozessorkerne. Jeder dieser Prozessoren kann einen Thread bearbeiten, in Summe werden in Echtzeit Programme gleichzeitig berechnet.
Open MP
Open MP wurde 1997 gemeinsam von Hardware- und Compilerherstellern entwickelt. Open MP ist eine Schnittstelle (API), mit der man Berechnungen in Schleifen auf mehrere Threads aufteilen kann. Eine Schleife wird so in mehreren Threads berechnet, diese Threads müssen dafür auf einen gemeinsamen Speicher zugreifen (Shared Memory). Für die Programmierung bedeutet das, dass man definieren muss, welche Variablen allen Threads zur Verfügung stehen und welche pro Thread sichtbar sind.
Das erste Beispiel
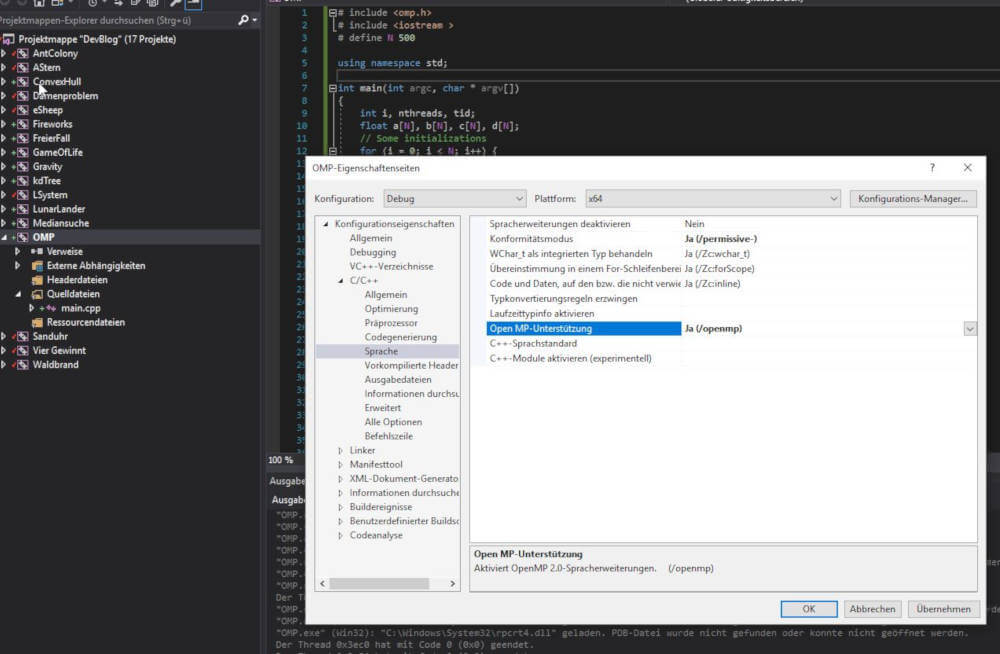
Ich habe in der Vorlesung zu „Effiziente Programmierung“ folgendes kurzes Beispiel implementiert. Das komplette Projekt findet man wie immer auf meiner GitHub Seite. Damit Open MP unter Visual Studio funktioniert muss es in den Einstellungen des Projekts aktiviert werden:
Hier der Code meines Beispiels:
# include <omp.h>
# include <iostream >
# define N 5
using namespace std;
int main(int argc, char * argv[])
{
int i, nthreads, tid;
float a[N], b[N], c[N], d[N];
// Some initializations
for (i = 0; i < N; i++) {
a[i] = i * 1.5f;
b[i] = i + 22.35f;
c[i] = d[i] = 0.0f;
}
# pragma omp parallel shared (a,b,c,d, nthreads ) private (i, tid )
{
tid = omp_get_thread_num();
if (tid == 0) {
nthreads = omp_get_num_threads();
cout << " Number of threads = " << nthreads << endl;
}
cout << " Thread " << tid << " starting ... " << endl;
# pragma omp sections nowait
{
# pragma omp section
{
cout << " Thread " << tid << " doing section 1" << endl;
for (i = 0; i < N; i++) {
c[i] = a[i] + b[i];
cout << " Thread " << tid << ": c[" << i << "]=" << c[i] << endl;
}
}
# pragma omp section
{
cout << " Thread " << tid << " doing section 2" << endl;
for (i = 0; i < N; i++) {
d[i] = a[i] * b[i];
cout << " Thread " << tid << ": d[" << i << "]=" << d[i] << endl;
}
}
} // end of sections
cout << " Thread " << tid << " done ." << endl;
} // end of parallel section
} // end of main
Ohne omp.h geht nix, mit diesem Header haben wir die Funktionalität der Open MP API zur Verfügung. Zuerst legen wir ein paar Variablen an. Die beiden Felder a und b werden initialisiert, c und d bleiben leer. c und d werden wir in zwei Schleifen berechnen, diese Schleifen werden parallelisiert.
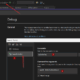
Mit dem #pragma omp parallel definieren wir einen Bereich, der nun parallelisiert wird. Mit shared() und private() legt man fest ob Variablen nur für den aktuellen Thread oder für alle sichtbar sind, also ob Variablen „shared“ sind. Danach legen wir zwei opm section mit einem pragma Statement an in denen jeweils eine Schleife definiert ist. Diese werden nun von Threads berechnet. Wie viele Threads, wann und wie lange diese rechnen übernimmt Open MP und ist von der ausführenden Hardware bzw. vom Betriebssystem abhängig. Bei mir unter Windows 10 und einem Quad Core (tatsächlich ein Dual Core mit Hyper-threading) erhalte ich folgende Ausgaben:

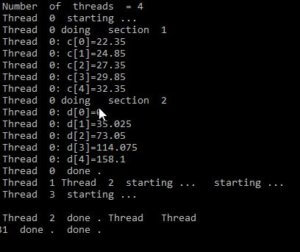

Man erkennt, die Ausgaben sind bei diesem einfachen Beispiel schon nicht vorauszusagen. Je nachdem wie die CPU ausgelastet ist werden Threads den Rechenkernen zugeordnet. Es gibt keine Garantie, dass ein Thread eine Berechnung allein durchführt. Das Betriebssystem kann den Thread beliebig zwischen den Kernen hin und her wechseln. Einmal rechnet nur Thread 0 und die 3 anderen machen nichts, dann rechnet hauptsächlich 0 und 2, dann wieder 3 und 2.
Fazit
Open MP ist in den meisten Compilern implementiert und erlaubt parallele Programmierung unter C++. Mit recht einfachen Mitteln lassen sich so Schleifen die lange rechnen auf mehrere Threads aufteilen. Dank dieser Optimierung gewinnt das ausgeführte Programm an Performance.
Im nächsten Artikel geht es um ein komplexes Beispiel das zeigt, dass man dank der Parallelisierung deutlich an Performance gewinnt.