Eigene Stable Diffusion LoRAs trainieren
In diesem Tutorial zeige ich wie man eigene Stable Diffusion LoRAs trainieren kann. Damit ist es beispielsweise möglich das eigene Gesicht dem Model beizubringen und somit KI generierte Bilder von sich selbst zu erstellen.
Eigene Stable Diffusion LoRAs trainieren
Es gibt einige unterschiedliche Möglichkeiten ein eigenes LoRA zu trainieren. Am einfachsten ist das Programm Kohya (Kohya auf GitHub). Mit diesen arbeite ich für dieses Tutorial.
Theorie
Bevor ich mit der Praxis beginne kurz die Theorie. Ein LoRA „Learn on Reconstruction and Attention“ ist eine Erweiterung für trainierte KI Modelle wie LLMs oder Stable Diffusion. Die Idee dahinter ist, das allgemeine Modell mit für einen bestimmten Anwendungsfall spezifischen Informationen zu verbessern. Eine Anwendung für Stable Diffusion wären Gesichter real existierender Menschen (siehe Paper).
Installation
Für Kohya benötigt man folgende Voraussetzungen:
- Git
- Visual Studio redistributable
- Python 3.10
Über den Link bekommt man den 64 Bit Installer für Windows. Die Installation muss mit Administratoren Rechte ausgeführt werden. Die Checkbox für „Add python.exe to PATH“ soll aktiviert werden.
Ich habe mir von der GitHub Seite die aktuellste Version von Kohya heruntergeladen und den Ordner entpackt. Im Verzeichnis findet sich eine setup.bat Datei die man ausführt.
Es werden nun einige zusätzliche Abhängigkeiten für Python installiert. Je nach Bandbreite dauert die Installation schon mal eine halbe Stunde oder länger.
Praxis
Kohya wird über die Datei gui.bat gestartet. Über mein PowerShell Terminal bekomme ich nützliche Informationen wie den Port unter dem die Applikation im Browser zu finden ist und auch ob meine Hardware korrekt erkannt wird. Wie im Screenshot zu sehen wird meine RTX 3080 Laptop Grafikkarte korrekt erkannt. D.h. ich beim Trainieren die weitaus effektivere GPU verwenden.
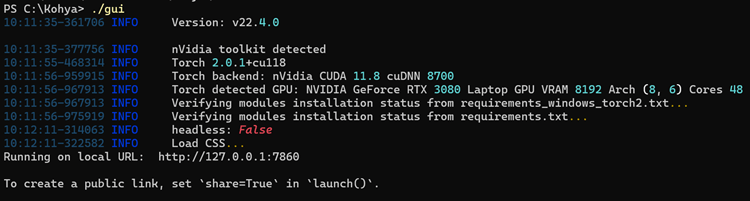
Wie zuletzt schon bei Comfy UI für Stable Diffusion läuft das Programm im Konsolenfenster als Webapplikation. Dort erfolgt die Ausgabe von Meldungen, die für uns wichtige ist die Port. Wir kopieren uns die URL (lokale IP Adresse + Port 7860) und öffnen diese in einem Browser. Dort wird das UI von Kohya geladen.

Daten
Bevor wir nun mit dem Trainieren vom LoRA Modell anfangen können benötigen wir Daten. Im Fall von Stable Diffusion sind das Bilder. Einer der Vorteile von LoRAs ist, dass man nur wenig Daten benötigt. Im Fall von einem Gesicht reichen rund 20 hochauflösende Bilder unterschiedlicher Posen. Kann man nicht auf so gutes Material zugreifen, dann benötigt man mehr Daten. Für Bilder mittlerer Qualität muss man mit 100 – 150 einzelne Bilder rechnen.
Als erstes legt man die vorgeschlagene Ordnerstruktur fest. D.h. in einem neuen Ordner lege ich mir die 3 Unterordner:
- image
- log
- mode
an.
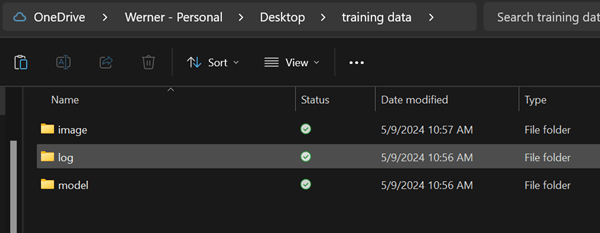
Im image Ordner legt man dann einen Ordner mit dem Namen: 100_My_Lora_Model an, in diesen kopiere ich meine gut 20 Bilder die ich von meinem Gesucht aus unterschiedlichen Positionen, zu unterschiedlichen Belichtungen / Tageszeiten und mit unterschiedlicher Kleidung an. Dafür habe ich in den letzten Wochen immer wieder Mal ein Selfie gemacht…
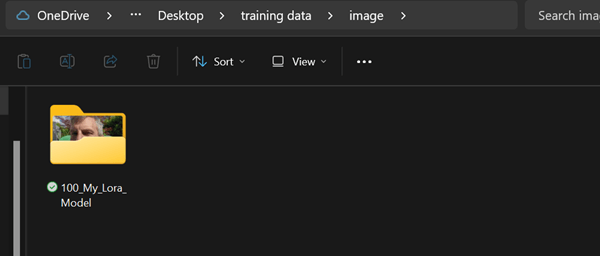
Der Name ist nicht zufällig gewählt. 100 ist die Anzahl an Trainingsschritte pro Bild. Hat man weniger Bilder machen auch 150 – 200 Sinn. Der Name vom Model wird durch Unterstrich gekennzeichnet an die Nummer angehängt. Für das Training benötigt man pro Bild ebenfalls eine Textdatei mit einer Beschreibung was auf dem Bild zu sehen ist. Für 20 Bilder ist das gerade noch möglich, bei mehreren 100 wird das schon mühsam. Zum Glück können wir das aber der KI überlassen, schließlich gehört die Bildkategorisierung und Beschreibung zu dessen Kernkompetenzen. Dazu nutzt man in Kohya BLIP.
Automatische Bildbeschreibung mittels BLIP
Unter dem Punkt Utilities findet sich bei Captioning das Tool BLIP Captioning. Dort wähle ich den Ordner mit meinen Trainingsdaten aus und klicke auf Caption images.
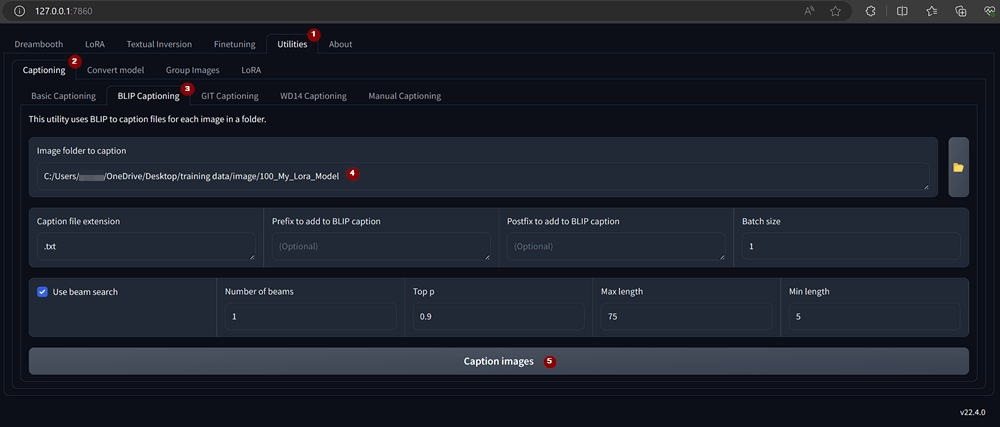
Ich hatte in meiner Kohya Version einige Probleme beim Generieren der Bildbeschreibungen. Meine Lösung beschreibe ich weiter unten, sollte das bei der aktuellen Version auch auftreten… Klappt alles ohne Probleme passiert im UI nichts, im offenen Terminal sieht man Aktivität. Führt man die Erkennung das erste mal aus, dann werden noch Abhängigkeiten installiert, weshalb man mehrere Minuten Wartezeit bis zum Ergebnis warten muss…

In meinem Fall hat die Beispielsweise folgende Beschreibung zu meinem Bild geliefert:

Bart habe ich auf dem Foto keinen, trotzdem lass ich das mal so stehen. Wer möchte kann die Beschreibungen nun pro Bild bearbeiten und so die Qualität vom Datensatz verbessern.
LORA trainieren
Mit den durch Beschreibungen aufgewerteten Datensatz kann man nun das erste LORA trainieren. Sofern man die Trainingsbilder nicht einheitlich in der Auflösung 512 x 512 Pixel hat muss die Option „Enable buckets“ aktiviert werden. Das ist vermutlich heute die Standardeinstellung, weil man sich nicht die Mühe machen möchte einen großen Datensatz an Bildern mühsam zu bearbeiten.

Bevor man nun das LoRA erstellt sollte man sich noch einen Überblick über die Optionen verschaffen und gegebenenfalls die Pfade anpassen. Bei mir sehen die Einstellungen so aus, ich habe meinen Trainingsdatensatz in den Kohya Hauptordner kopiert:
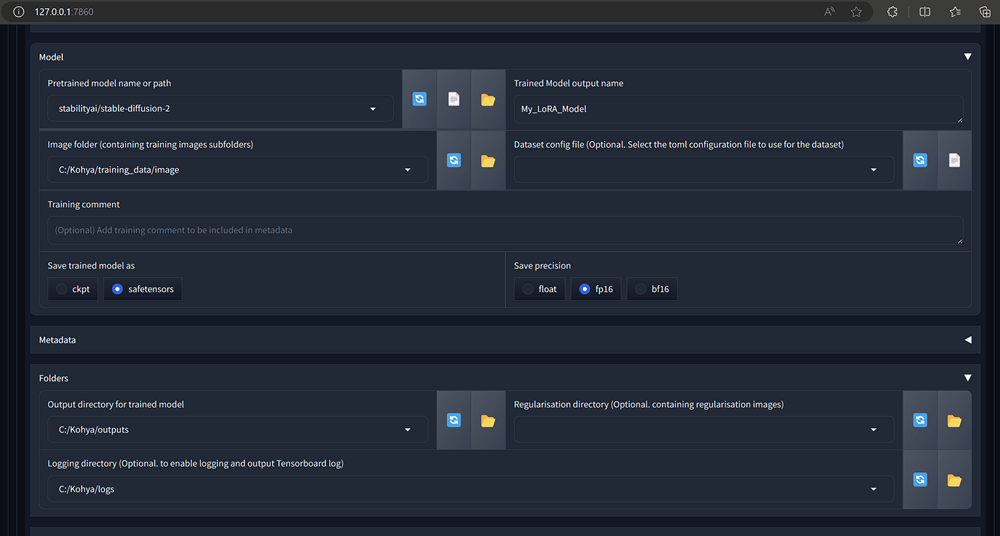
Eine der wichtigsten Einstellungen ist die Wahl des „Pretrained model“. Das ist jenes Model, von dem aus man ein LoRA erstellen möchte und für dieses man das LoRA auch verwenden will. Für realistische Bilder ist das aktuell Stable Diffusion 2, möchte man Fantasy Charaktere erstellen verwendet man Stable Diffusion XL Base, alternativ lädt man sich ein bereits passendes Model aus das man verwenden will (z.B. von civitai.com).
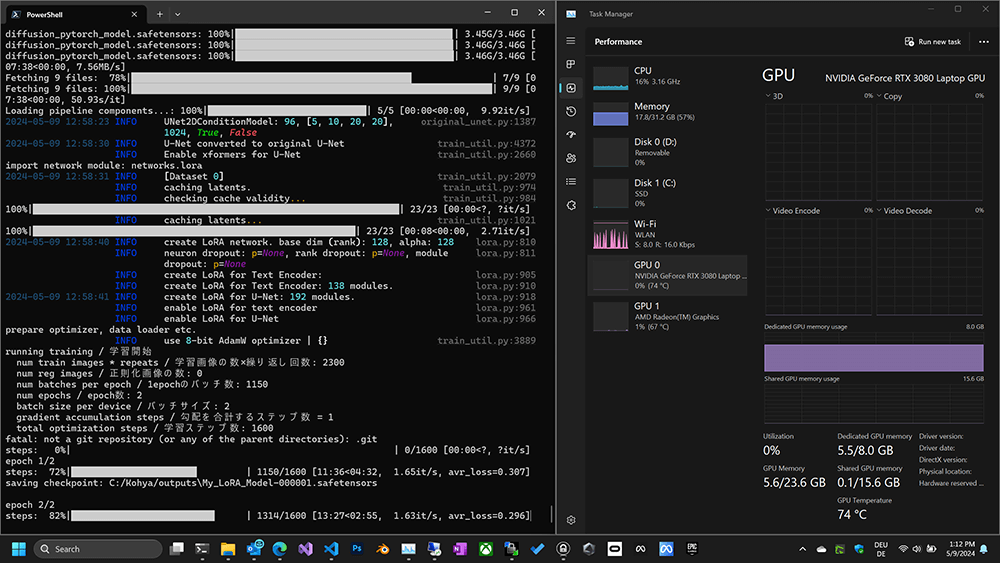
Bei mir hat das Training auf einer NVIDIA 3060 über nach gedauert. Ganze 10 Stunden wurde bei voller Last gerechnet. Nach dem Training findet man das erstellte LoRA Model im outputs Ordner von Kohya:
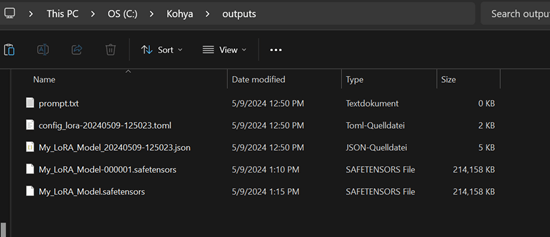
Eigenes LoRA Model verwenden
Fehlt nur noch der erste Test mit dem Model. Dazu verwende ich ComfyUI. In meinem Testlauf habe ich einige Selfies von mir erstellen lassen… richtig spannend:






Mit meinem LoRA kann ich mir nun schnell beliebige Profilbilder generieren. Je nach eingegebenen Prompt lässt man seinen personalisierten Avatar auch jünger oder älter aussehen. Wer noch kreativer ist, der bastelt sich mit einem spezialisierten Model wie beispielsweise Dreamshaper seinen eigenen Orc, Elf oder anderen Sci-Fi oder Fantasy Charakter.
Problemlösungen
Im folgenden Beschreibe ich alle Lösungen dich ich für die Probleme gefunden habe die ich bis zum fertigen Modell auf meinem Laptop hatte.
BLIP funktioniert nicht
In meiner getesteten Kohya Version 24.1.2 fehlte der sd_scripts Ordner, der Tools liefert für BLIP. Deshalb habe ich dieses Git Repository im Kohya Ordner mit dem Namen sd_scripts entpackt:
Nachdem ich das BLIP Captioning neu ausgeführt hatte stand folgender Fehler im Terminal:
NameError: name 'is_url' is not defined

In diesem Fall findet ein Script im sd-scripts/finetune Ordner eine Abhängigkeit im sd-scripts/library Ordner nicht. Eine einfache Lösung ist es, den sd-scripts/library Ordner nach sd-scripts/finetune/library zu kopieren. Danach hats es geklappt.
Fazit
In über 1000 Wörter habe ich sehr ausführlich gezeigt wie man sich ein LoRA mit dem eigenen Gesicht für Stable Diffusion trainiert. Jeder Stable Diffusion und Comfy UI Nutzer sollte sich zumindest ein solches LoRA zulegen. Man lernt sehr viel und dank dem Model ist mein Aussehen nun für die KI verewigt.




ich habe ein absolutes problem mit dem erstellen, ich weiß nicht wieso aber mein lora wird immer katastrophal. möchte eine ki frau erstellen aber das lora sieht am ende nicht ansatzweise aus wie die bilder, manchmal wird es sogar nur ein klumpen, ich verstehe nicht was ich falsch mache 🙁