Game of Life in C++
Meine Game of Life Implementierung in C++ unterscheidet sich etwas von herkömmlichen Visualisierungen. In der Lehrveranstaltung „Effiziente Programmierung“ ging es um Optimierung von C++ Code und insbesondere darum wie man in C++ Bereiche der Berechnung parallelisiert. Schneller und effizienter – der Wettbewerb war eröffnet.

Game of Life in C++
Wie kann man die Berechnung von Felder der Dimension 2 dank Multicore Prozessoren beschleunigen? Einfache Programme laufen in einem Thread auf einem Prozessor. Sobald man jedoch CPU-lastige Berechnungen durchführt die Sekunden dauern sollte man ans parallelisieren denken. Im letzten Artikel habe ich euch bereits Open MP vorgestellt und gezeigt wie man damit in C++ Schleifen parallelisiert. In diesem konkreten Beispiel wird die Berechnung des 2 dimensionalen Feldes für den Game of Life Algorithmus (oder zu deutsch Spiel des Lebens – vielleicht könnt ihr euch noch an meine Implementierung für den Raspberry Pi erinnern?) dank Open MP deutlich schnell. Wir können aber noch mehr optimieren.
Implementierung ohne Parallelisierung
Bevor wir uns in die Optimierung stürzen benötigen wir erst einmal eine Software. Aus diesem Grund beginnt man mit einem Programm und achtet gar nicht auf die spätere Parallelisierung. Ich habe dazu ein Konsolenprogramm implementiert, dass Game of Life Felder erstellen kann und diese über viele Generationen weiter Berechnet. Das Programm ist dabei so dynamisch, dass es vollständig über Parameter gesteuert wird. Eine grafische Ausgabe gibt es nicht, der Spielstand wird aber in einer Textdatei abgelegt. Es ist möglich Spielfelder anzulegen, die mehrere Tausend Felder breit und hoch sind. Damit kann man sowohl Hauptspeicher als auch CPU gehörig auslasten!
Zu finden ist das Programm wie immer auf meiner GitHub Seite. Den Code werde ich im Detail hier nicht besprechen. Es gibt 3 Klassen:
- bitboard
repräsentiert ein N*N großes quadratisches Feld aus Bits. Diese Bits werden als dynamic_bitset der Boost Bibliothek angelegt. - gol
Game of Life relevanter Code der ein bitboard setzt und über die evoluteBoard Methode in einen Folgezustand rechnet. - application
der gesamte Applikations relevante Code wie beispielsweise Ausgabe des Zustands in eine Datei und die Performance Messung.
Details sind im Source Code nachzulesen.
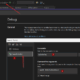
Der erste Testlauf zeigt und mit den gegebenen Parametern folgendes Bild. Was hat das Programm gemacht?
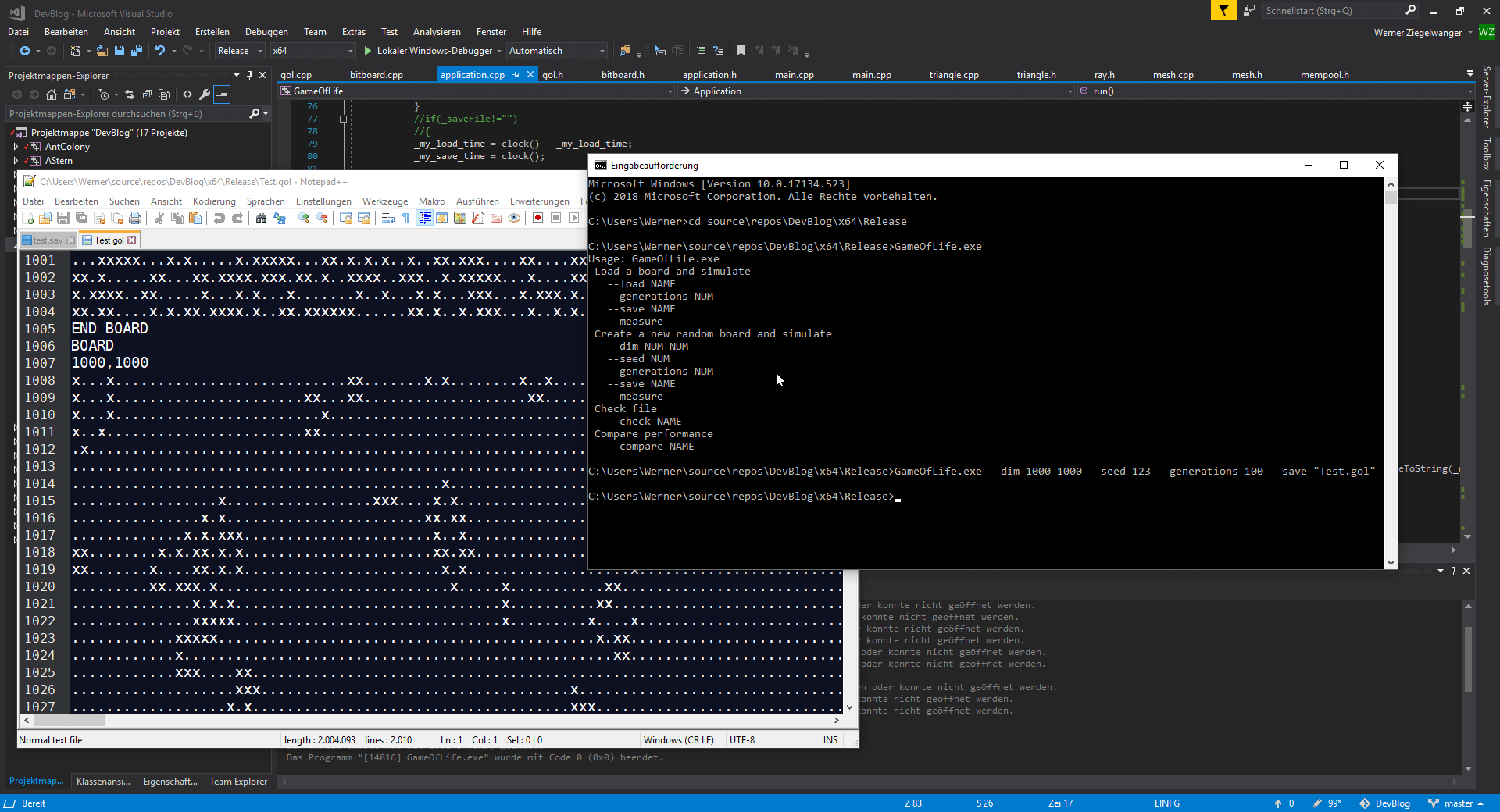
Ich habe die Release Version gestartet und dabei folgende Parameter verwendet:
GameOfLife.exe --dim 1000 1000 --seed 123 --generations 100 --save "Test.gol"
Es wird ein neues zufälliges Board der Dimension 1000 x 1000 Zeichen erstellt. Der seed Wert ist dazu da, dass das Board zwar zufällig erstellt wird, jedoch durch Angabe des selben seed Wertes auch bei mehrfacher Ausführung immer das selbe. Zusätzlich geben wir an, dass das Programm 100 Generationen rechnen soll. Die Ausgabe des Start- und Endboards erfolgt in die angegebene Datei Test.gol. Der Screenshot zeigt neben dem Aufruf auch die Ausgabedatei. Das Board oben war noch recht ausgeglichen mit „.“ und „x“ gefüllt, das Endboard nach 100 Generationen zeigt die für Game of Life üblichen Strukturen.
Implementierung mit Parallelisierung
Wir haben nun also ein Konsolenprogramm, welches in einer Schleife (Generationen) sehr CPU-lastige Berechnungen ausführt. Perfekt geeignet um durch eine Parallelisierung mit OpenMP unter C++ maximalen Nutzen zu ziehen. Die Änderungen in der zweiten verbesserten Version sind nur wenige – der Nutzen enorm. Konkret wurden in der GOL::evoluteBoard() Methode folgende zwei OMP Zeilen hinzugefügt:
// omp code for parallelize loop
# pragma omp parallel
{
#pragma omp for
for (int i = 0; i < in->getWidth(); ++i)
for (int j = 0; j < in->getHeight(); ++j)
out->set(i, j, in->stayAlive(i, j));
}Und schon wird die Schleife für die Berechnung des nächsten Zustands eines N*N Boards auf die einzelnen Prozessorkernen (sofern verfügbar) aufgeteilt. Da genau dieser Code die größte CPU Auslastung verursacht ist mit der Parallelisierung von nur einer einzigen Schleife das Programm massiv beschleunigt worden. Man könnte nun noch weitere Schleifen parallelisieren, der Gewinn wäre aber gemessen am Aufwand gering. Es ist vollkommen ausreichend nur die Bottlenecks im Programm zu beheben.
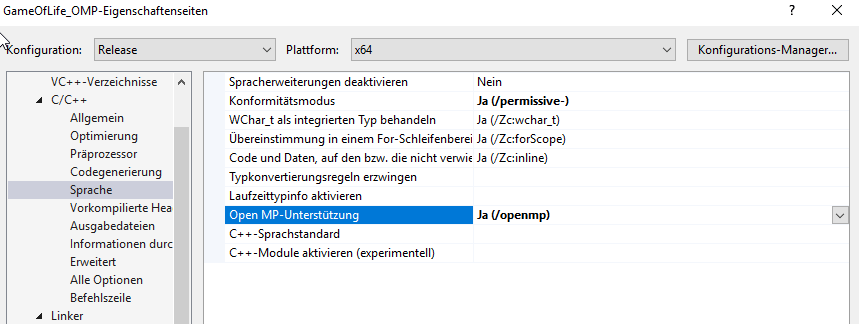
Beim Erstellen vom Programm müsst ihr unbedingt den Open MP Support aktivieren, ansonsten werdet ihr enttäuschende Ergebnisse bei den Laufzeittests bekommen:
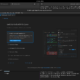
Vergleich
Der direkte Vergleich der Release Version zeigt bei meinem System folgendes Bild:

Der Vergleich zeigt auf einen Blick schon einen deutlichen Unterschied zwischen parallelisiertem Code und normalem. In Zahlen ausgedrückt:
- auf meinem i7 errechnet man 1000 Generationen eines 1000×1000 Boards in 24 Sekunden
- im durch Open MP optimiertem Code braucht man für die selbe Berechnung 14 Sekunden
Auf meinem System verringert sich die Laufzeit auf fast die Hälfte (58%). Dieser Wert ist abhängig von der Anzahl an zu rechnenden Generationen, der Größe vom Board und der Hardware, auf dem das Programm läuft. Aus diesem Grund werdet ihr vermutlich andere Werte haben. Es zeigt sich in jedem Fall eine deutliche Verbesserung nur durch 2 hinzugefügten Codezeilen!
Achtung: ohne Plan nun alle Schleifen zu parallelisieren kann negative Auswirkungen haben. Open MP hat bei der Ausführung einen kleinen Overhead. Bei Schleifen die nur ein paar Durchläufe haben kann das zu einer längeren Laufzeit führen. Es macht deshalb nur sinn die Bottlenecks zu überarbeiten.
Fazit
Open MP am Beispiel eines Game of Life in C++ implementiert zeigt wie man durch minimale Code Änderungen die Ausführungszeit extrem beschleunigen kann. Mein Beispiel zeigt eine Verbesserung der Laufzeit auf die Hälfte. Je mehr Kerne das System hat und je mehr Schleifendurchläufe Berechnet werden müssen, desto krasser kann dieser Vergleich ausfallen.
Was sind eure Werte? Wer hat die Hardware auf dem dieser Code am schnellsten läuft?