C++ Graph Performance Test
In diesem C++ Graph Performance Test zeige ich euch die Ergebnisse meiner Recherche zu Graphen in C++. Das Ziel war zu ermitteln, ob eine Graph Struktur Vorteile in der Geschwindigkeit der Berechnungen bringt und wie diese ausfallen.
C++ Graph Performance Test
Die Graphentheorie wurde schon früh von der Informatik aufgegriffen und eingesetzt. Bekannt sind vor allem die auf einen Graphen als Datenstruktur aufbauenden Algorithmen wie:
- das Travel-Salesman-Problem
- der Dijkstra Suchalgorithmus
- A*-Algorithmus zur Pfadsuche in Computerspielen
- uvm….
Offenbar kann man in so einem Graphen recht effizient navigieren und Daten suchen. Doch ist er auch dafür geeignet um ein einem Programm die Businessdaten im Hauptspeicher zu halten? Das will ich mit meinem Test herausfinden.
Die Implementierung zu dieser Aufgabenstellung findest du wie immer auf meiner GitHub Seite. Der Code darf gerne verwendet werden!
Problem
Für den Performance Test habe ich mir ein praxisnahes Beispiel ausgedacht. Der Graph soll Daten von Fußballern halten und damit arbeiten. In meinem Beispiel wird also eine Struktur aus:
- 250 Ländern
- 2 Ligen pro Land
- 18 Teams pro Liga
- 20 Spiele pro Team
In einer Graphenstruktur ergibt das ein Gebilde aus 189751 Knoten. Der eine zusätzliche Knoten ist übrigens der Wurzelknoten an dem alles zusammenläuft. Im Gegensatz dazu wird zum Vergleich diese Struktur in einer verschachtelten Klassenhierarchie abgebildet. D.h. ein Land hat eine Liste zugeordneter Ligen, eine Liga eine Liste zugeordneter Teams usw.
Für den Performancetest habe ich folgende Aufgabenstellungen für diese Datenstruktur erstellt:
- Suche nach Spielern mit einem zuvor zufällig gewählten Nachnamen
für jeden gefundenen Spieler wird neben dem gesamten Namen auch noch das zugehörigen Daten zu Team, Liga und Land ausgegeben - alle Spieler eines zufällig gewählten Teams ausgeben
- ein zufälliger Spieler wechselt das Team
Lösung
Bei der Implementierung habe ich nach Möglichkeit aktuelle C++ Konstrukte aus der STL wie Lambdas und Algorithmen verwendet.
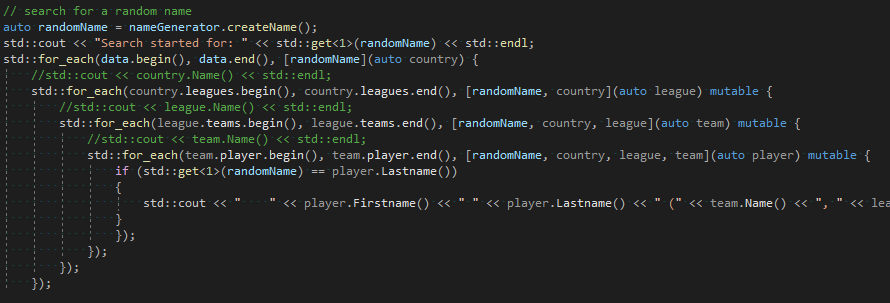
Es findet sich beispielsweise kein einziger Pointer im Programm. Außerdem habe ich den Source Code wieder für Windows und Linux entwickelt, wobei der Linux Code von Visual Studio Remote am Raspberry Pi compiliert und getestet wurde.
Es gibt zwei Klassen die die jeweilige Datenstruktur erstellen:
- ClassHierarchyFactory
erstellt eine Klassenhierarchie mit der angegebenen Struktur und gibt einen std::vector mit allen Ländern zurück. - GraphFactory
erstellt einen Graphen mit der angegebenen Struktur und Graphen zurück.
Für den Graphen wird die Boost Graph Library verwendet. In einem Folgeartikel werde ich noch genauer darauf eingehen.
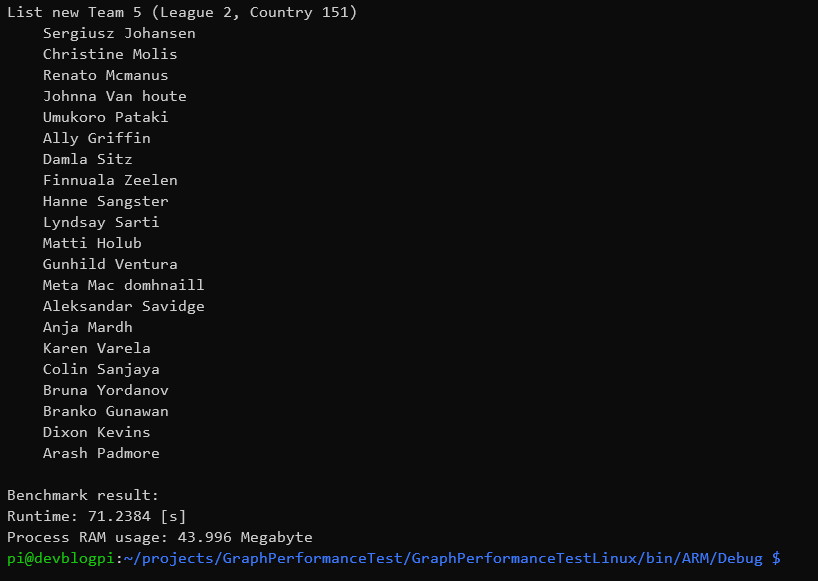
Die Benchmark Messung ist wie folgt implementiert:
- Ausführungszeit vom Start der Erstellung der Datenstruktur bis zur Erfüllung der letzten Aufgabe wird mit der steady_clock der STL chrono Klasse ermittelt
- den vom Prozess genutzten RAM wird zum Ende der Berechnung ausgegeben. Je nach Betriebssystem (Windows oder Linux) in der dafür vorgesehenen Weise.
Bewertung
Bei so großen Datenstrukturen zeigt sich ein massiver Unterschied zwischen Debug und Release Version. Auf meinem System im Debug Modus dauert jeder der beiden Steps 30 – 40 Sekunden zur Ausführung und benötigt bis zu 250 MB Speicher. Im Gegensatz dazu ist die Release Version nach nicht mal 3 Sekunden für alle Berechnungen fertig und brauch maximal ein Fünftel des Speichers.
Wie zu erwarten ist die Suche im Graphen wesentlich performanter als in der Klassenstruktur und der Teamwechsel eines Spieler durch umsetzen einer Kante quasi ohne Aufwand. Im Debugmodus fällt das in der Laufzeit noch massiv ins Gewicht, in der optimierten Release Version ist der Unterschied erst auf der zehntel Sekunde sichtbar.
Fazit
Der Graph benötigt zur Laufzeit mehr Speicher, ist aber bei darauf ausgeführten Algorithmen wesentlich schneller. Als Entwickler muss man sich zwischen Speicher und Geschwindigkeit entscheiden und die optimale Lösung für das Problem finden. Obwohl der Graph mit knapp 200000 Knoten nicht klein ist, benötigt er doch vernachlässigbar viel mehr Speicher. Ich denke im Big Data Einsatz könnte sich diese Vorgehensweise lohnen. Diese Einschätzung korreliert mit den Daten die man in der Literatur findet. No-SQL Strukturen haben bei komplexen Anfragen (der Freund eines Freund eines Freund eines Freund im Facebook Graphen) deutlich besser als bei herkömmlichen SQL Datenbanken. Vergleichbar ist dafür mein kleines Graphen und Klassenhierarchie Beispiel.
Wo würdest du eher einen Graphen als eine Klassenhierarchie verwenden? Welche Vorteile könnte die Klassenhierarchie haben?