ComfyUI Stable Diffusion Interface
Mit dem ComfyUI Stable Diffusion Interface kann man sich ohne große Vorkenntnisse den KI Bildgenerator auch am eigenen Rechner aufsetzen. Ich zeige welche Schritte dafür nötig sind.

ComfyUI Stable Diffusion Interface
Um mit der rasanten Entwicklung im Bereich künstlicher Intelligenz mitzuhalten bedarf es einigen Aufwands. Nachdem ich nun zahlreiche theoretische Kurse absolviert hatte war die Zeit reif für die Praxis. Doch wie beginnt man? Von 0 weg eine neue KI trainieren? Die KI Modelle sind heute schon soweit, dass man diese in der Praxis nutzen kann, ohne diese selber mit Daten zu trainieren. Aus diesem Grund steht für mich der Fokus darauf mit einem Open Source KI Modell zu arbeiten oder im besten Fall eines der LLMs mit eigenen Daten anzureichern.
Stable Diffusion
Da ich mich in meiner Freizeit in letzter Zeit kreativer beschäftige ist das Open Source KI Modell von Stability AI mit dem Namen „Stable Diffusion“ die Wahl. Mit ihm kann man Bilder erzeugen, besonders bekannt ist aktuell die Möglichkeit aus einer Textbeschreibung ein quadratisches Bild zu erstellen. Unterschiedliche Plattformen bieten dieses Service aktuell unterschiedlich konfiguriert an, Beispiele sind:
- Dall-E
- Midjourney AI
- Leonardo AI
- …
Je nach Nutzungsgrad ist das Service gratis bis kostenpflichtig. Möchte man die volle Kontrolle und das Service selber konfigurieren mit unterschiedliche trainierten Modellen, dann benötigt man einen leistungsstarken Rechner (idealerweise eine Nvidia Grafikkarte mit mindestens 8 GB RAM) und etwas Zeit sich in die Thematik einzuarbeiten.
Comfy UI
Comfy UI ist ein Frontend Programm für den Webbrowser in dem Stable Diffusion über einen grafischen Node Editor konfiguriert und nutzt. Mit diesem grafischen Editor lässt sich der Bildgenerator schnell, einfach und vor allem ohne Programmierkenntnisse konfigurieren. Einzig das initiale Setup ist nicht ganz trivial.
Installation
Der erste Schritt ist nun eine aktuelle Version von Comfy UI herunterzuladen. Comfy UI wird Open Source entwickelt und man findet das Projekt auf der beliebten GitHub Plattform. Das ist der Link auf die aktuellen Releases. Ich habe mir eine aktuelle Version heruntergeladen und das Archiv am Rechner entpackt. Bei mir sieht das nun so aus:
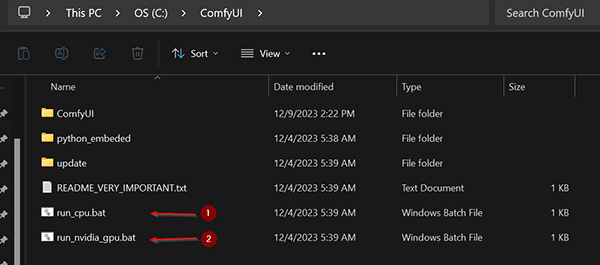
Das Programm wird über einen der beiden Links gestartet:
- startet das Programm für die Berechnung mit der CPU
- startet das Programm für die Berechnung mit einer Nvidia GPU
sofern man eine Nvidia Grafikkarte mit mindestens 8 GB VRAM besitzt ist diese Option zu empfehlen. Aktuell kann man noch nicht viel machen, das Programm ist noch „nackt“, es fehlen die KI Modelle.
KI Modelle hinzufügen
Die aktuelle Version von Stable diffusion findet man auf huggingface.co beim Hersteller Stability AI. Dort kann man alle nötigen AI Modelle heruntergeladen werden. Derzeit aktuell ist die SDXL Version, aber so schnell sich das aktuell ändert wird zum Zeitpunkt des Lesens dieses Artikels vermutlich schon wieder eine neue Version online sein. Aktuell erscheint rund jedes halbe Jahr eine neue große Version.
Was brauche ich?
Damit wir mit Stable Diffusion XL und ComfyUI beginnen können müssen 2 große Dateien heruntergeladen werden, das sind die trainierten KI Modelle und ein VAE (Variational autoencoder).
Insgesamt sind das in der aktuellen Version rund 13 GB. Wohin mit den Dateien? Das base Model und der refiner kommen in den models/checkpoints Ordner

Das VAE kopiert man in den models/vae Ordner
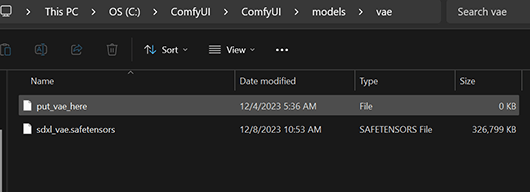
Sollte man nun Comfy UI neu starten werden die Models bereits erkannt und man kann diese nutzen.
Mein erstes AI generiertes Bild
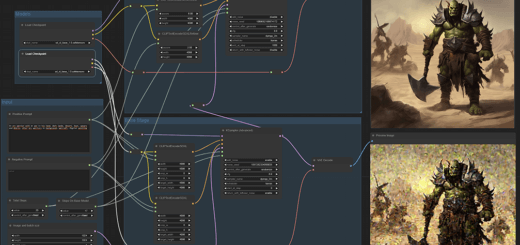
Das folgende Bild zeigt einen Default workspace von Comfy UI mit dem man bereits die ersten Bilder erstellen kann:

Startet man Comfy UI über die Kommandozeile über das *.bat File, dann öffnet sich der Browser mit dem User Interface. Solange der Server im Hintergrund läuft erreicht man das UI immer über die Adresse 127.0.0.1:8188. Mit einem Klick auf „Load Default“ lädt man das im Bild zu sehende Flow Chart. Ganz links beim Checkpoint wählt man das base Model. Im CLIP Text Encode gibt man den Text für das zu erstellende Bild ein, da kannst du selber kreativ werden. Über das zweite CLIP Text Encode darunter wählt man den negativen Prompt, also alles, was nicht im Bild sein soll. Ein Klick auf „Queue Prompt“ und das Bild wird generiert. Es wir im „Save image“ Knoten nach einigen Sekunden angezeigt.
Für Fortgeschrittene
Ich nehme an du hast nun bereits ein erstes eigenes Bild mit SDXL erstellt. Damit fängt der Spaß erst an, denn wir nutzen aktuell nur das base Modell mit den default Einstellungen. Das Bild kann mit dem refiner weiter verbessert werden. Es können beliebig viele Knoten in den Prozess der Bilderstellung eingebunden werden. Ein Beispiel siehst du beim Cover Bild des Artikels. Es gibt kein Erfolgsrezept, es gibt nun viele Möglichkeiten wie man zu einer schönen Ausgabe kommt. Beispiele findet man im Internet über die Suche nach „ComfyUI workspace“. Ein Flow Chart kann man über „Load“ von einer JSON oder PNG Datei geladen werden. Eine sehr gute Ausgangsbasis sind die Beispiele von ThinkDiffusion.
Fazit
Mit Comfy UI kann man das Stable Diffusion KI Modell zuhause am eigenen Rechner nutzen. Das ist vollkommen gratis und erlaubt durch eine manuelle Konfiguration die Erstellung von Bildern die über Services nicht erlaubt oder möglich wären. Außerdem kann man nun endlich seine teure Grafikkarte sinnvoll nutzen.